在Python中处理重复数据涉及到数据的识别和删除,这通常在数据预处理阶段进行。以下是在Python中处理重复数据的一些常用方法:
1.使用pandas库:
导入pandas库
```python
import
pandas
as
pd
```
读取数据,例如从CSV文件中读取
```python
df
=
pd.read_csv('data.csv')
```
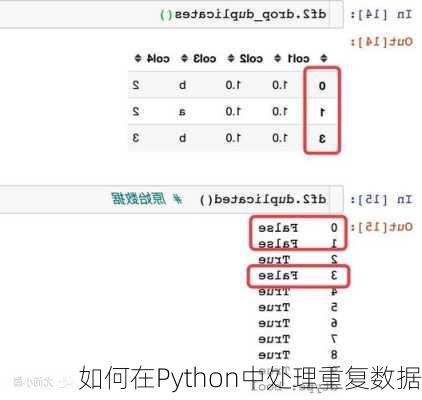
查找重复行
```python
duplicates
=
df.duplicated()
```
显示重复行
```python
duplicate_rows
=
df[duplicates]
```
删除重复行(默认保留第一次出现的行)
```python
df.drop_duplicates(inplace=True)
```
2.使用SQLAlchemy(适用于数据库操作):
导入SQLAlchemy库
```python
from
sqlalchemy
import
create_engine
```
创建数据库连接
```python
engine
=
create_engine('sqlite:///data.db')
```
删除重复记录(以SQLite为例)
```python
query
=
"DELETE
FROM
tablename
WHERE
id
NOT
IN
(SELECT
MIN(id)
FROM
tablename
GROUP
BY
column1,
column2)"
engine.execute(query)
```
3.使用MySQLdb(适用于MySQL数据库操作):
导入MySQLdb库
```python
import
MySQLdb
```
连接到MySQL数据库
```python
db
=
MySQLdb.connect(host="localhost",
user="root",
password="password",
db="database_name")
cursor
=
db.cursor()
```
查找并删除重复记录
```python
cursor.execute("DELETE
FROM
tablename
WHERE
id
NOT
IN
(SELECT
MIN(id)
FROM
tablename
GROUP
BY
column1,
column2)")
db.commit()
```
4.使用
Ingore、ReplaceInto
等关键字(适用于MySQL数据库操作):
当插入数据时遇到主键冲突,可以使用
Ingore
或
ReplaceInto
等关键字来处理重复数据。这通常在执行批量插入操作时使用。
这些方法可以根据具体场景和需求进行选择和组合使用。需要注意的是,在删除重复数据之前,最好先备份原始数据,以防需要恢复或进行其他操作。