在pandas中,可以使用`read_excel()`函数来读取Excel文件。如果想要分块读取Excel文件,可以结合使用`chunksize`参数。以下是一个示例:
```python
import
pandas
as
pd
设置块大小
chunksize
=
1000
读取Excel文件,分块处理
for
chunk
in
pd.read_excel('example.xlsx',
chunksize=chunksize):
对每个数据块进行操作
例如,将每个块写入到新的Excel文件中
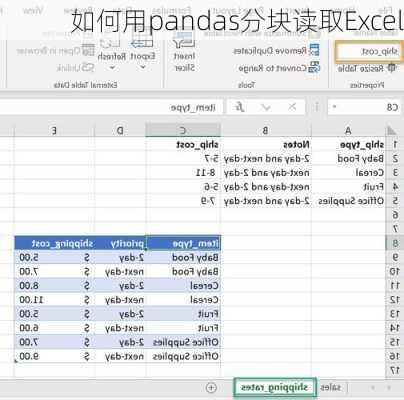
chunk.to_excel('chunked_example.xlsx',
index=False)
```
在这个示例中,`chunksize`被设置为1000行,这意味着每次迭代将从Excel文件中读取1000行数据,并作为一个单独的数据块返回。你可以调整`chunksize`的值以适应你的内存大小和处理需求。
注意,上述代码将覆盖原有的'chunked_example.xlsx'文件。如果你希望追加写入,可以将`index=False`改为`mode='a'`。