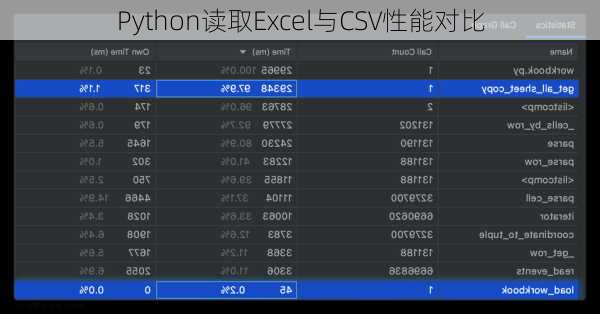
在Python中,读取Excel和CSV文件的性能取决于所使用的库及其内部实现。对于CSV文件,Python内置的`csv`模块通常效率较高,因为CSV文件通常比Excel文件更轻量级,解析起来相对容易。而对于Excel文件,特别是较新格式的`.xlsx`文件,由于其基于ZIP压缩的复杂性,读取可能会更加耗时。
以下是使用Python处理这两种文件的一些常见方法:
```python
import
csv
with
open('example.csv',
'r')
as
file:
reader
=
csv.reader(file)
for
row
in
reader:
print(row)
```
```python
import
pandas
as
pd
df
=
pd.read_csv('example.csv')
print(df)
```
```python
import
pandas
as
pd
df
=
pd.read_excel('example.xlsx')
print(df)
```
```python
from
openpyxl
import
load_workbook
wb
=
load_workbook('example.xlsx')
sheet
=
wb.active
for
row
in
sheet.iter_rows(min_row=1,
max_col=sheet.max_column,
max_row=2,
values_only=True):
print(row)
```
在实际应用中,读取CSV文件通常会比读取Excel文件更快,尤其是在处理大量数据时。然而,这还取决于文件大小、数据复杂性以及你如何处理这些数据。如果你在读取文件后立即对数据进行操作,那么操作本身的开销可能会超过单纯读取文件的开销。
为了获得最佳性能,你应该尽可能优化数据读取过程,例如通过限制读取特定的列或行范围,或者在可能的情况下,将数据缓存到内存中以避免重复读取磁盘。
最后,值得注意的是,对于非常大的文件,即使CSV文件通常解析速度较快,但如果文件过大,仍然有可能导致内存不足或其他性能问题。在这种情况下,你可能需要考虑使用更高效的数据读取策略,比如分块读取数据,或者使用更高效的数据存储格式,如Parquet或HDF5。