统计字段缺失的解决方案
在数据分析过程中,我们可能会遇到数据缺失的问题。数据缺失可能会影响我们的分析结果,因此需要寻找合适的解决方案。以下是几种处理字段缺失的常见方法:
当遇到历史数据缺少字段的问题时,可以使用脚本来解决。这种方法的步骤包括:确定缺少字段的数据范围,创建新表来存储缺少字段的数据,编写脚本将新表与原表进行比较,找出缺少的字段,并将它们添加到新表中,最后运行脚本并验证结果。
数据清洗是数据分析过程中不可或缺的环节,它涉及到对数据进行重新审查和校验,发现并纠正数据文件中可识别的错误,按照一定的规则把错误或冲突的数据洗掉。在数据清洗的过程中,可以对不完整的记录进行删除或填充处理。此外,还可以使用统计分析的方法识别错误值或异常值,并进行相应的处理。
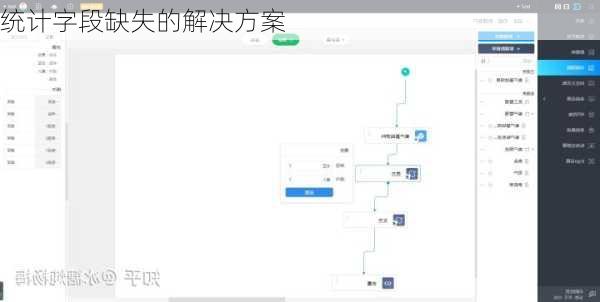
通过编写SQL语句,可以选择图表类型,拖动和缩放图表生成自己的报表或大屏页面。在SQL查询中,可以编写逻辑来补全缺失的分类或时间。例如,可以使用CASE语句来处理缺失值,或者使用UNION
ALL与FULL
JOIN
ON来合并多个表并处理缺失值。
有一种专利技术可以通过查询数字型字段缺失统计缺失,这种技术可能涉及到特定的查询技巧或者算法。
Pandas是一个强大的数据处理库,提供了丰富的汇总统计和计算方法,以及处理缺失值的操作。例如,可以使用sum()和cumsum()方法来计算缺失值,使用idxmax()方法来找到缺失值的最大值,使用unique()和value_counts()方法来统计缺失值,使用isin()方法来筛选缺失值等。
在选择上述方法之一时,需要根据实际情况和数据特点来决定。同时,为了避免类似问题的发生,建议在数据采集和处理过程中加强数据质量控制,并定期进行数据审计。