尊敬的用户,您好!根据您提供的查询“GPU集群管理案例”,我为您找到了以下有关GPU集群管理案例的参考资料。在这些参考资料中,您可以了解到关于GPU集群管理的实践案例、解决方案以及相应的管理工具。
首先,根据搜索结果[1],在当前市场上有多种GPU集群解决方案,其中包括:
1.NVIDIADGX:这是一款由NVIDIA推出的集成多个GPU的服务器,可提供高性能计算、深度学习和大规模数据分析等功能。
2.GoogleCloud:谷歌云平台提供了GPU集群的解决方案,用户可通过租赁来获取高性能GPU资源,实现机器学习、图像处理等需求。
3.AWSEC2:AmazonWebServices(AWS)提供了适用于深度学习和科学计算等应用领域的GPU实例,用户可自主选择适合自己需求的GPU规格。
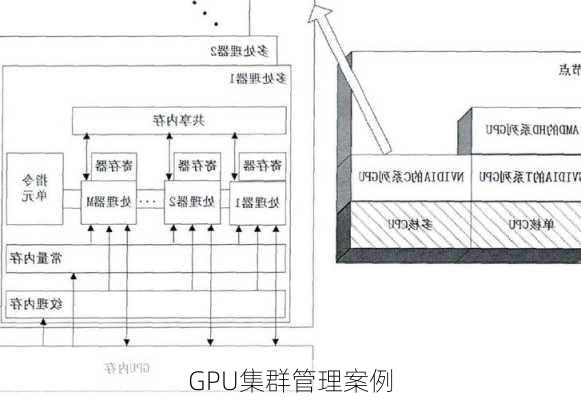
4.AliyunGPU集群:阿里云GPU集群可为各种机器学习、科学研究和渲染应用提供强大支持,并允许用户根据实际情况对GPU数量进行灵活配置。
5.IBMPowerSystems:IBMPowerSystems提供了针对AI和深度学习业务的基于NVIDIATeslaV100GPU的系列产品,具备高带宽内存、快速互连和加速存储技术,能够支持各种大型工作负载。
此外,搜索结果[2]提供了一篇关于GPU集群管理、使用指南的文章。该文章介绍了如何选择、安装和配置GPU集群,以及如何使用虚拟机练习Linux操作系统的使用,同时给出了关于配置网络环境SSH、安装操作系统等方面的内容。
在搜索结果[7]中,曙光自主研发的集群管理软件GridView支持GPU计算监控,用户可随时了解GPU软硬件信息,如GPU的型号、软件版本、主频、风扇转速和温度变化等。这也是一种GPU集群管理案例。
最后,搜索结果[9]提到了微软开源分布式GPU集群管理平台OpenPAI,它能提高GPU的利用率,管理训练任务,从而加速深度学习。
综上所述,您可以从以上参考资料中了解到不同厂商和平台提供的GPU集群管理案例及其解决方案。希望这些信息能够帮助您更好地了解GPU集群管理方面的实践案例。如果您还有其他问题或需求,请随时告诉我,我会竭诚为您提供帮助!