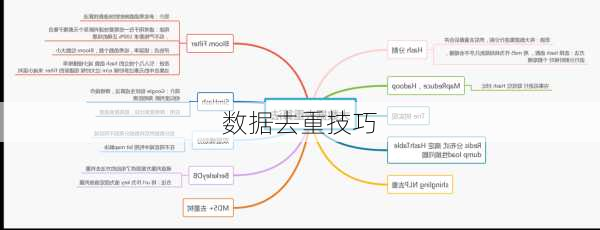
数据去重技巧
数据去重是数据分析和处理中的一个重要环节,它可以有效地减少数据冗余,提高数据质量和分析效率。以下是根据搜索结果整理的一些数据去重的技巧:
DataFrame
去重
在Python中,可以使用pandas库的`drop_duplicates()`方法对DataFrame进行去重。这个方***返回一个新的DataFrame,其中包含了原DataFrame中的唯一行。例如,你可以这样做:
```python
import
pandas
as
pd
df.drop_duplicates(inplace=True)
```
这里,`inplace=True`表示去重操作将在原DataFrame上进行,如果不设置该参数,则会返回一个新的DataFrame。
数据去重
在SQL中,可以使用`DISTINCT`关键字进行数据去重。例如,如果你有一个名为`students`的表,你想找出唯一的`student_id`,你可以这样做:
```sql
SELECT
DISTINCT
student_id
FROM
students;
```
此外,你还可以使用`GROUP
BY`语句配合`HAVING
COUNT(*)
=
1`来实现去重。
数据去重
在Excel中,可以使用“删除重复项”功能进行数据去重。你只需要选择你需要去重的列,然后在“数据”菜单中选择“删除重复项”即可。此外,还可以使用VBA编写宏来自动化这个过程。
数据去重
在大数据处理中,可以使用MapReduce框架来进行数据去重。具体的实现方式是,将数据分发到不同的reduce节点上,每个节点只处理一个key(即一个数据),这样就可以确保每个数据只会被处理一次。
SQL
数据去重
在使用Flink
SQL时,你可以使用`DISTINCT`关键字进行数据去重。例如,如果你想从一个名为`tt_source`的表中找出唯一的行,你可以这样做:
```sql
SELECT
DISTINCT
*
FROM
tt_source;
```
此外,你还可以使用`FIRST_VALUE`
UDAF函数根据主键进行去重。
以上是一些常见的数据去重技巧,具体的选择取决于你的数据规模、数据特性以及你的计算资源。希望这些信息能对你有所帮助。